LFM2
LFM2 ist ein neues Modell von Liquid Foundation Models, das die schnellste On-Device-Generative-AI-Erfahrung bietet und eine 3-fache Verbesserung der Trainingseffizienz im Vergleich zur vorherigen Generation aufweist.
Aufgeführt in Kategorien:
Künstliche IntelligenzEntwicklungOpen Source

Beschreibung
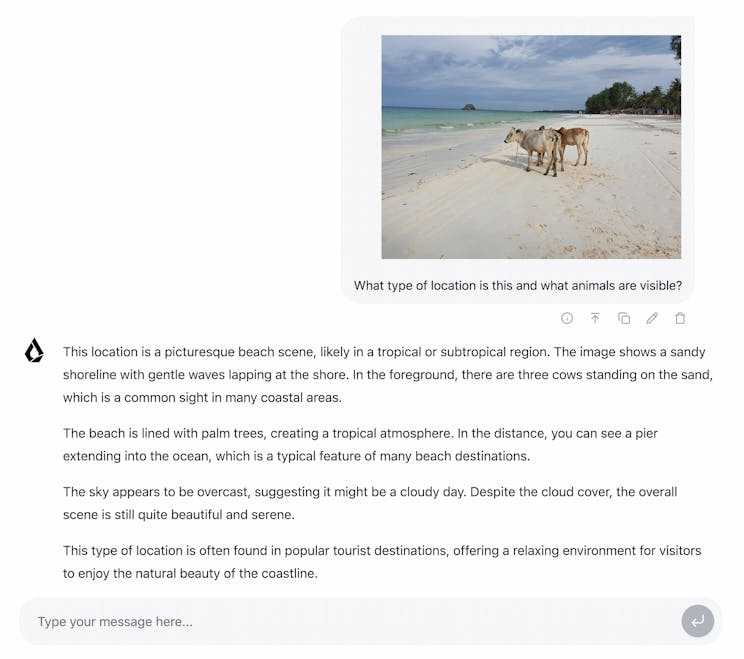
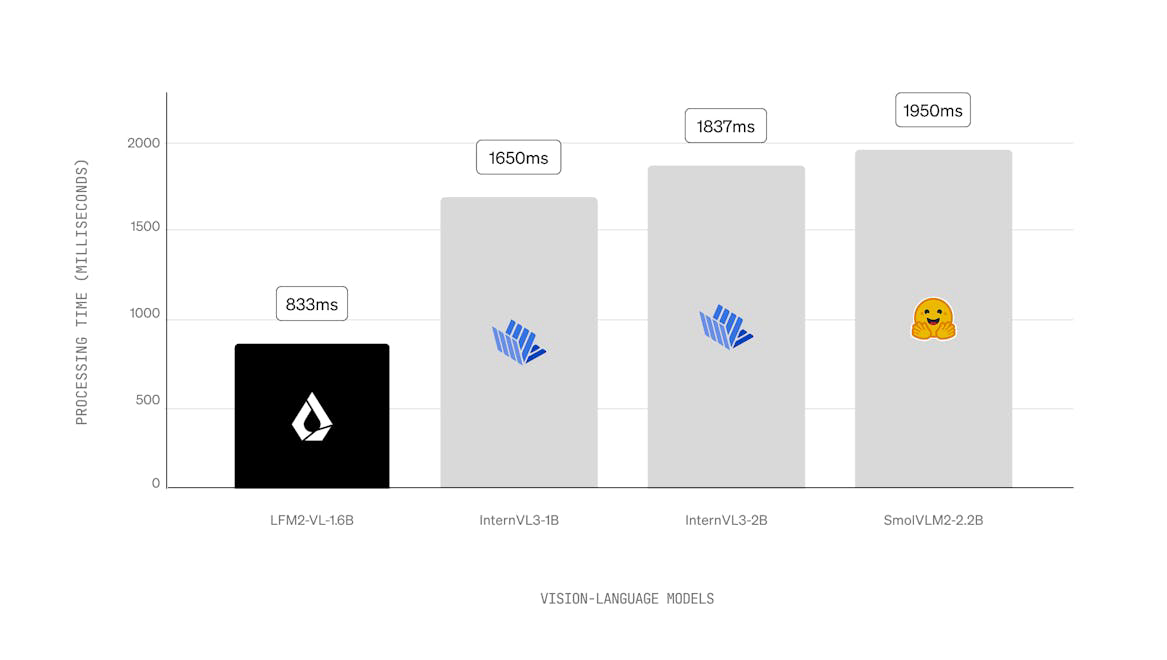
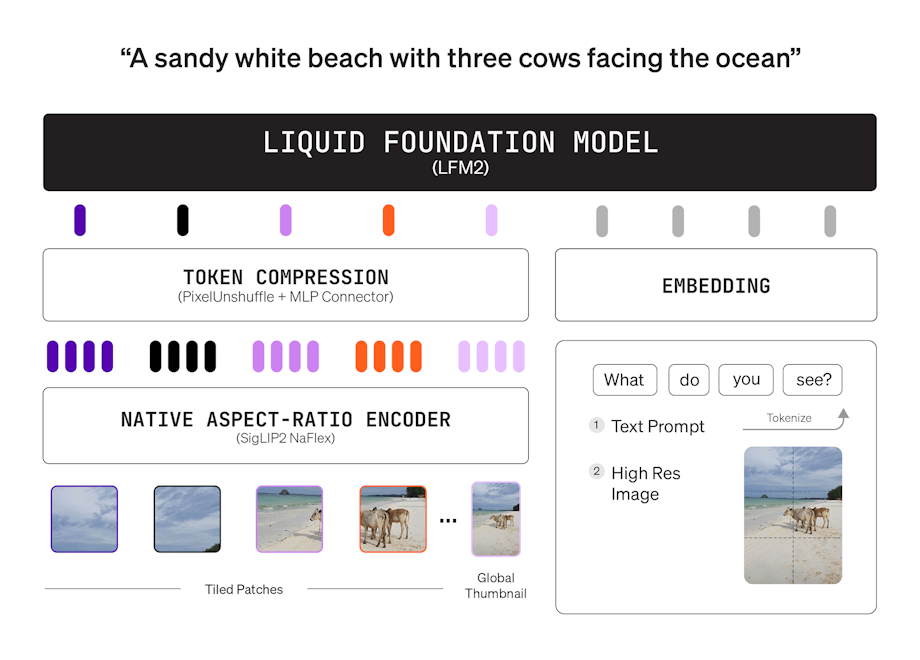
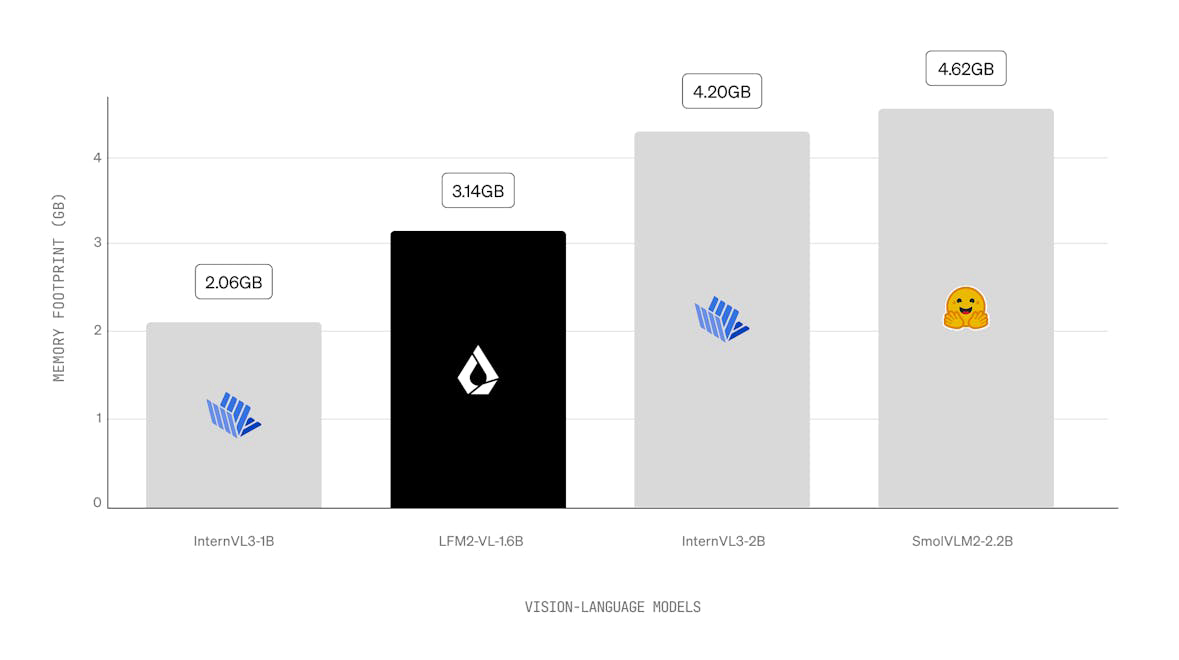
LFM2 ist eine neue Klasse von Liquid Foundation Models (LFMs), die einen neuen Standard in Qualität, Geschwindigkeit und Speichereffizienz für generative KI auf Geräten setzt. Entwickelt für die schnellste KI-Erfahrung auf Geräten, bietet LFM2 eine 2x schnellere Dekodierungs- und Vorbefüllungsleistung als sein Vorgänger, Qwen3, auf CPU. Mit einer hybriden Architektur übertrifft es Modelle in jeder Größenklasse erheblich und ist ideal für lokale und Edge-Anwendungsfälle. LFM2 erreicht eine 3x Verbesserung der Trainingseffizienz im Vergleich zu früheren Generationen und bietet einen kosteneffizienten Weg zum Aufbau leistungsfähiger KI-Systeme für allgemeine Zwecke.
Wie man benutzt LFM2?
LFM2-Modelle können privat und lokal auf Geräten mit Integrationen wie llamacpp getestet werden. Benutzer können die Modelle auch für spezifische Anwendungsfälle mit TRL anpassen. Für maßgeschneiderte Lösungen werden die Benutzer ermutigt, das Vertriebsteam zu kontaktieren.
Hauptmerkmale von LFM2:
1️⃣
2x schnellere Dekodierungs- und Vorbefüllungsleistung als Qwen3 auf CPU
2️⃣
3x schnellere Trainingseffizienz im Vergleich zur vorherigen LFM-Generation
3️⃣
Hybride Architektur mit multiplikativen Toren und kurzen Faltungen
4️⃣
Flexible Bereitstellung auf CPU-, GPU- und NPU-Hardware
5️⃣
Optimiert für Echtzeit-Überlegungen in verschiedenen Geräten wie Smartphones und Robotern.
Warum könnte verwendet werden LFM2?
| # | Anwendungsfall | Status | |
|---|---|---|---|
| # 1 | Lokale und Edge-KI-Anwendungen in der Unterhaltungselektronik | ✅ | |
| # 2 | Echtzeit-Überlegungen für Robotik und intelligente Geräte | ✅ | |
| # 3 | Bereitstellung in den Bereichen Finanzen, E-Commerce und Bildung. | ✅ | |
Wer hat entwickelt LFM2?
Liquid AI Inc. hat sich der Entwicklung von Fundamentmodellen verschrieben, die Qualität, Latenz und Speicher für spezifische Aufgaben und Hardwareanforderungen ausbalancieren. Sie arbeiten mit Fortune-500-Unternehmen zusammen, um ultra-effiziente multimodale Fundamentmodelle mit einem sicheren, unternehmensgerechten Bereitstellungsstapel bereitzustellen.