LFM2
New generation of hybrid models for on-device edge AI
Listed in categories:
Artificial IntelligenceDevelopmentOpen Source

Description
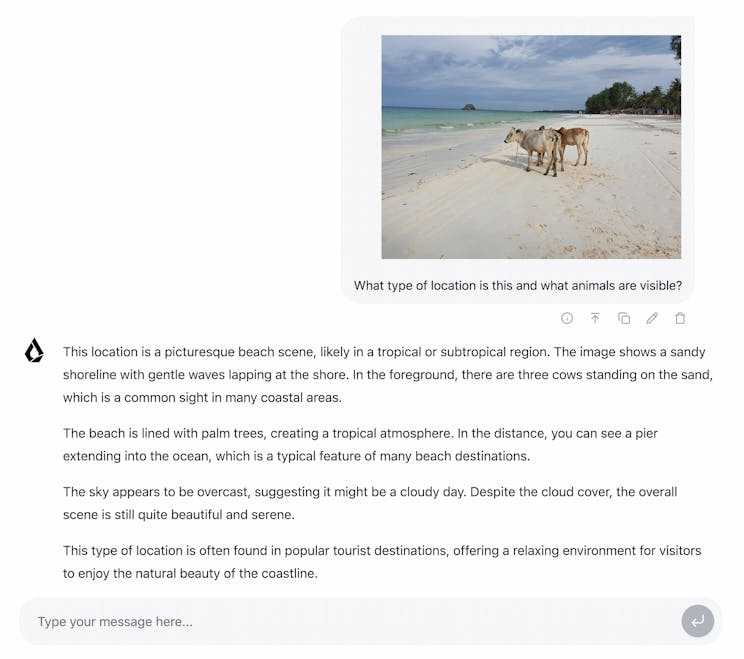
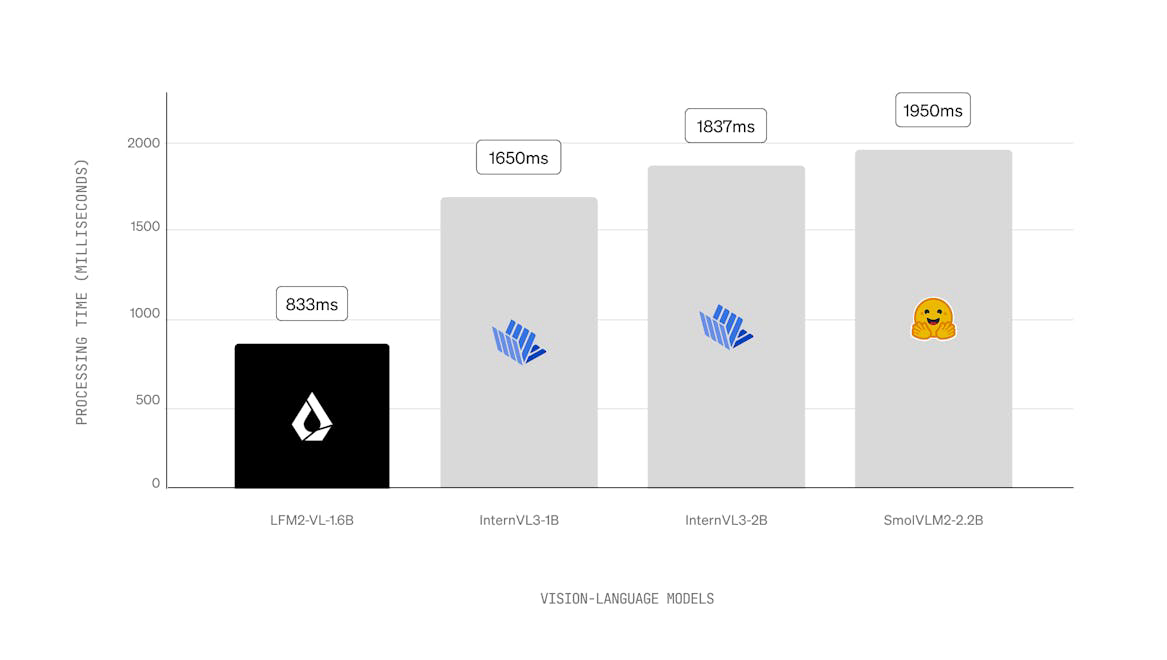
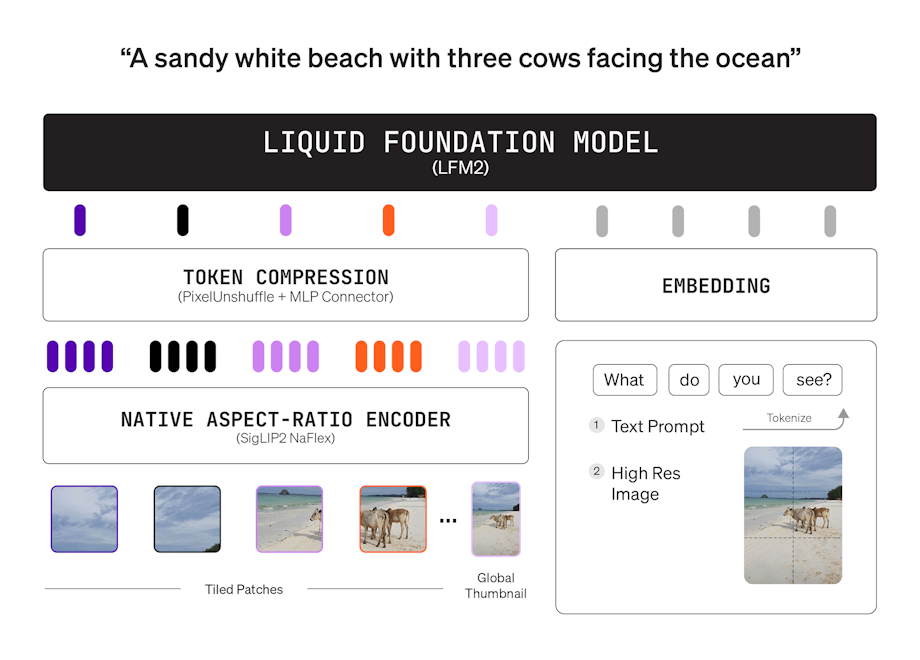
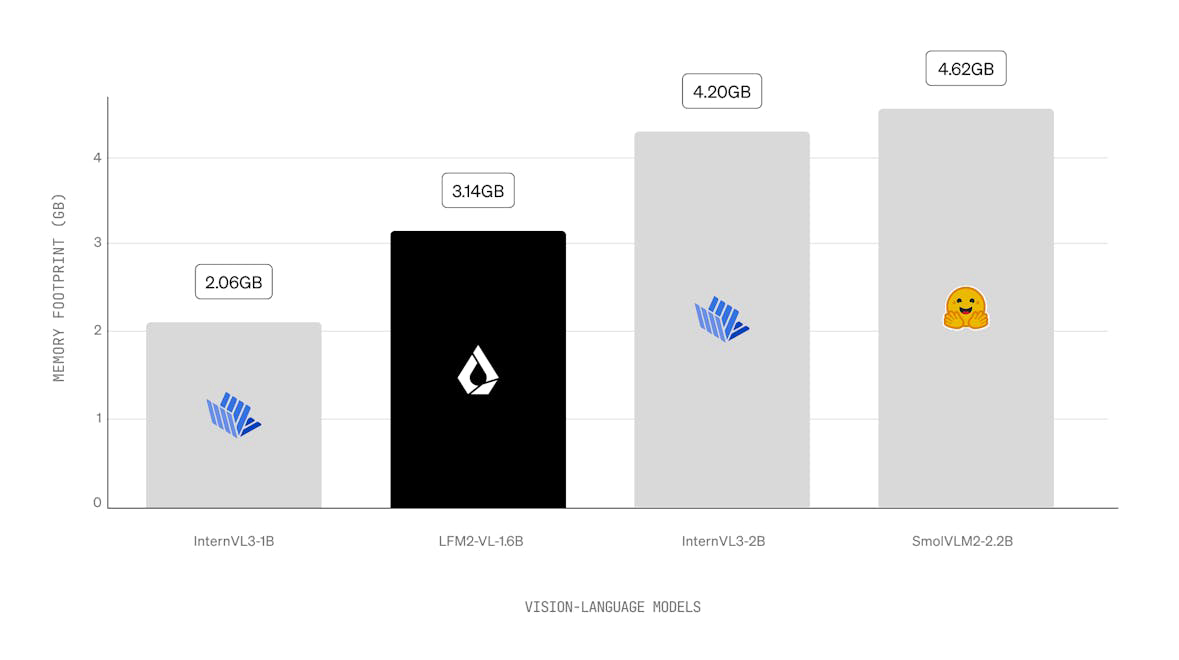
LFM2 is a new class of Liquid Foundation Models (LFMs) that sets a new standard in quality, speed, and memory efficiency for on-device generative AI. Designed for the fastest on-device AI experience, LFM2 delivers 2x faster decode and prefill performance than its predecessor, Qwen3, on CPU. With a hybrid architecture, it significantly outperforms models in each size class, making it ideal for local and edge use cases. LFM2 achieves a 3x improvement in training efficiency over previous generations, providing a cost-effective path to building capable general-purpose AI systems.
How to use LFM2?
LFM2 models can be tested privately and locally on devices using integrations like llamacpp. Users can also fine-tune the models for specific use cases with TRL. For custom solutions, users are encouraged to contact the sales team.
Core features of LFM2:
1️⃣
2x faster decode and prefill performance than Qwen3 on CPU
2️⃣
3x faster training efficiency compared to previous LFM generation
3️⃣
Hybrid architecture with multiplicative gates and short convolutions
4️⃣
Flexible deployment on CPU, GPU, and NPU hardware
5️⃣
Optimized for real-time reasoning in various devices like smartphones and robots.
Why could be used LFM2?
| # | Use case | Status | |
|---|---|---|---|
| # 1 | Local and edge AI applications in consumer electronics | ✅ | |
| # 2 | Real-time reasoning for robotics and smart appliances | ✅ | |
| # 3 | Deployment in finance, e-commerce, and education sectors. | ✅ | |
Who developed LFM2?
Liquid AI Inc. is dedicated to building foundation models that balance quality, latency, and memory for specific tasks and hardware requirements. They engage with Fortune 500 companies to provide ultra-efficient multimodal foundation models with a secure enterprise-grade deployment stack.