ScrapeLoop
Chuyển đổi bất kỳ trang web nào thành nguồn dữ liệu trong vài phút. Trích xuất dữ liệu có cấu trúc mà không cần mã hóa.
Liệt kê trong các danh mục:
SaaS

Mô tả
ScrapeLoop là một nền tảng thu thập dữ liệu web không cần mã hóa cho phép người dùng biến bất kỳ trang web nào thành nguồn dữ liệu có cấu trúc chỉ trong vài phút. Với giao diện đơn giản chỉ cần nhấp và chọn, người dùng có thể tự động hóa quy trình thu thập dữ liệu của mình mà không cần kiến thức lập trình. Nền tảng này được thiết kế để dễ sử dụng, cung cấp các tính năng như tạo API ngay lập tức, tích hợp trực tiếp với Google Sheets và khả năng thu thập dữ liệu từ các trang được bảo vệ bằng mật khẩu.
Cách sử dụng ScrapeLoop?
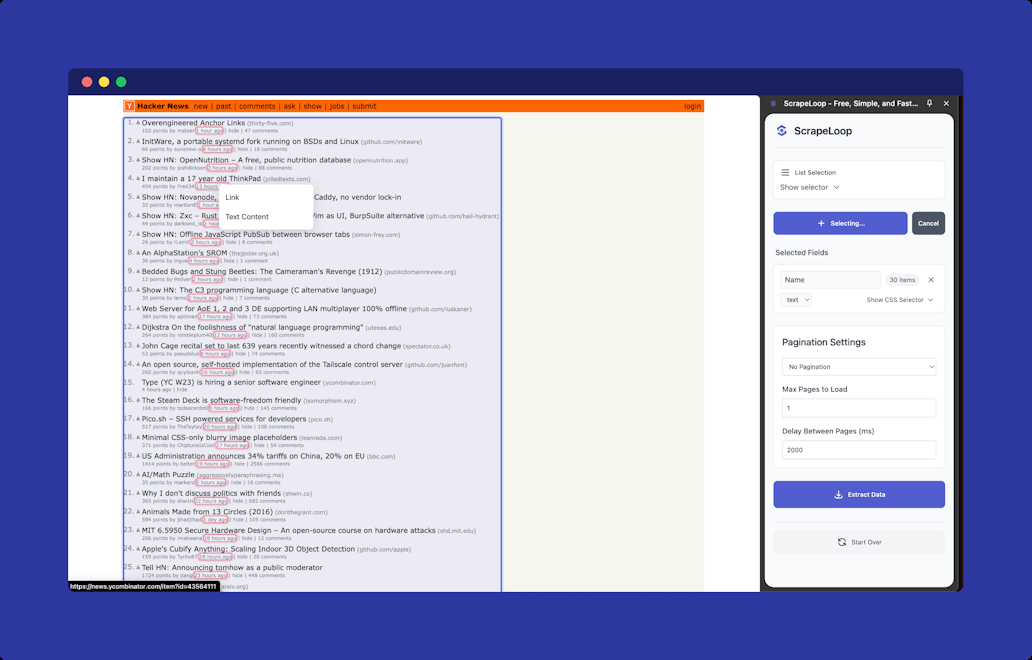
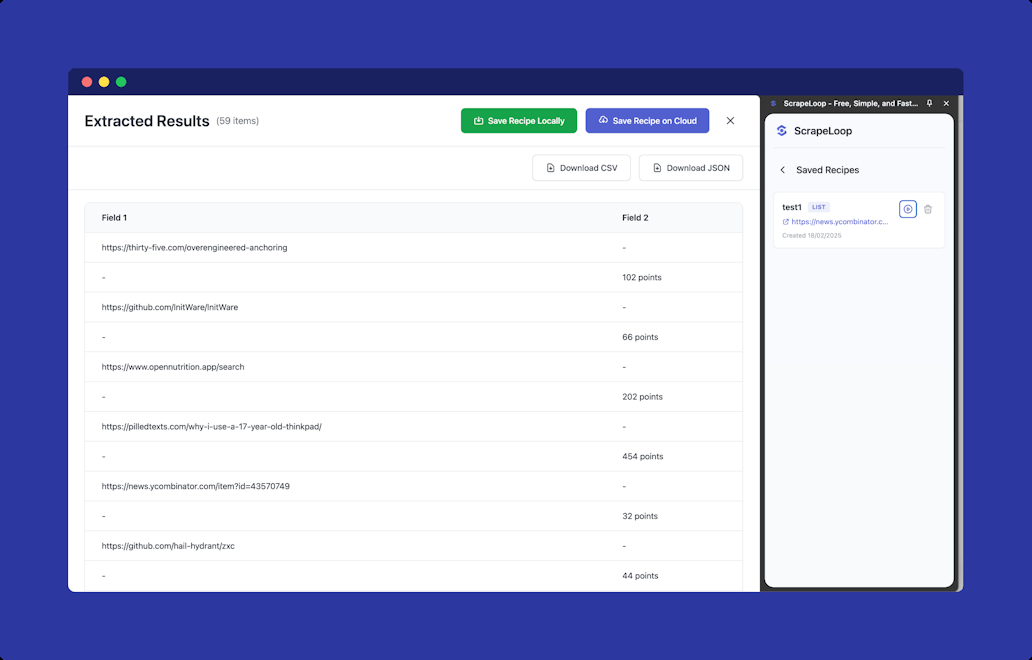
Để sử dụng ScrapeLoop, chỉ cần cài đặt tiện ích mở rộng Chrome, chọn dữ liệu bạn muốn trích xuất bằng cách nhấp vào nó và thiết lập lịch thu thập dữ liệu của bạn. Nền tảng sẽ tự động xử lý phần còn lại, cung cấp cho bạn dữ liệu có cấu trúc theo thời gian thực.
Tính năng chính của ScrapeLoop:
1️⃣
Thu thập dữ liệu web chỉ cần nhấp và chọn
2️⃣
Quy trình thu thập dữ liệu tự động
3️⃣
Tạo API ngay lập tức
4️⃣
Tích hợp trực tiếp với Google Sheets
5️⃣
Hỗ trợ thu thập dữ liệu từ các trang sau đăng nhập
Tại sao nên sử dụng ScrapeLoop?
| # | Trường hợp sử dụng | Trạng thái | |
|---|---|---|---|
| # 1 | Thông tin thương mại điện tử để theo dõi giá cả và hàng tồn kho của đối thủ | ✅ | |
| # 2 | Tìm kiếm khách hàng bằng cách trích xuất thông tin liên hệ doanh nghiệp | ✅ | |
| # 3 | Phân tích thị trường để thu thập dữ liệu và thông tin thị trường theo thời gian thực | ✅ | |
Do ai phát triển ScrapeLoop?
ScrapeLoop được phát triển bởi một đội ngũ cam kết đơn giản hóa việc thu thập dữ liệu web cho các doanh nghiệp. Họ tập trung vào việc tạo ra các công cụ thân thiện với người dùng giúp người dùng tự động hóa quy trình thu thập dữ liệu mà không cần kiến thức kỹ thuật.