
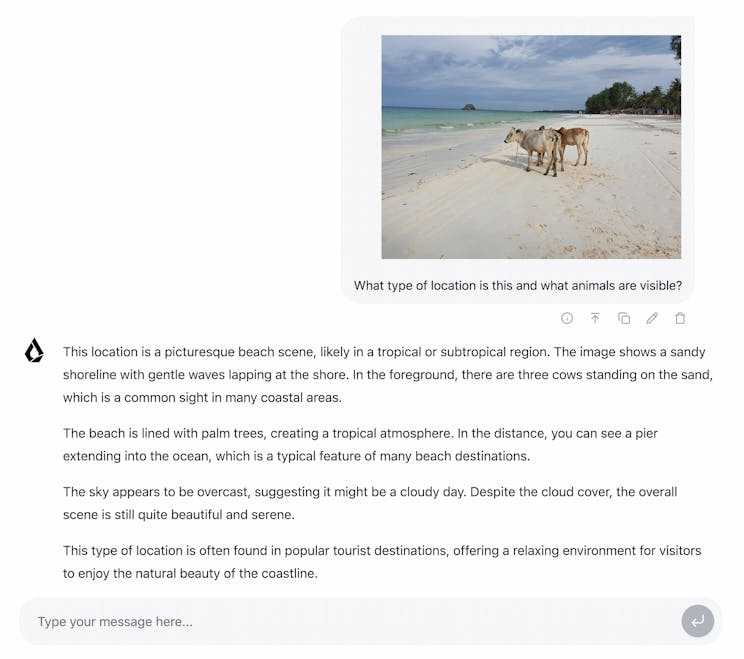

描述
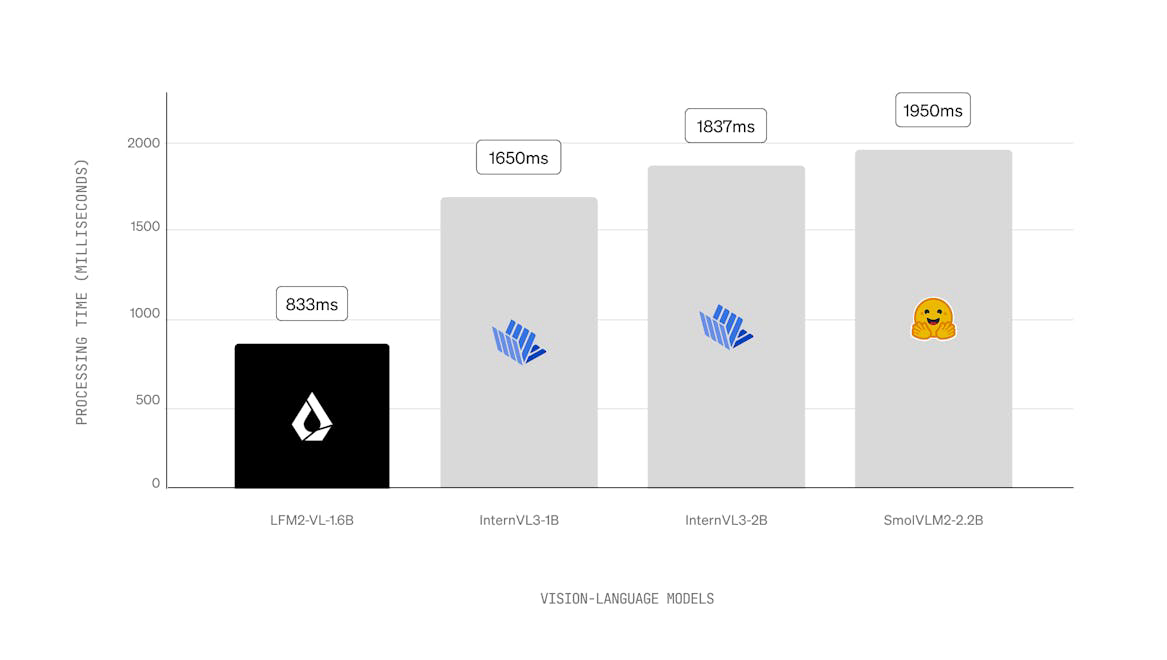
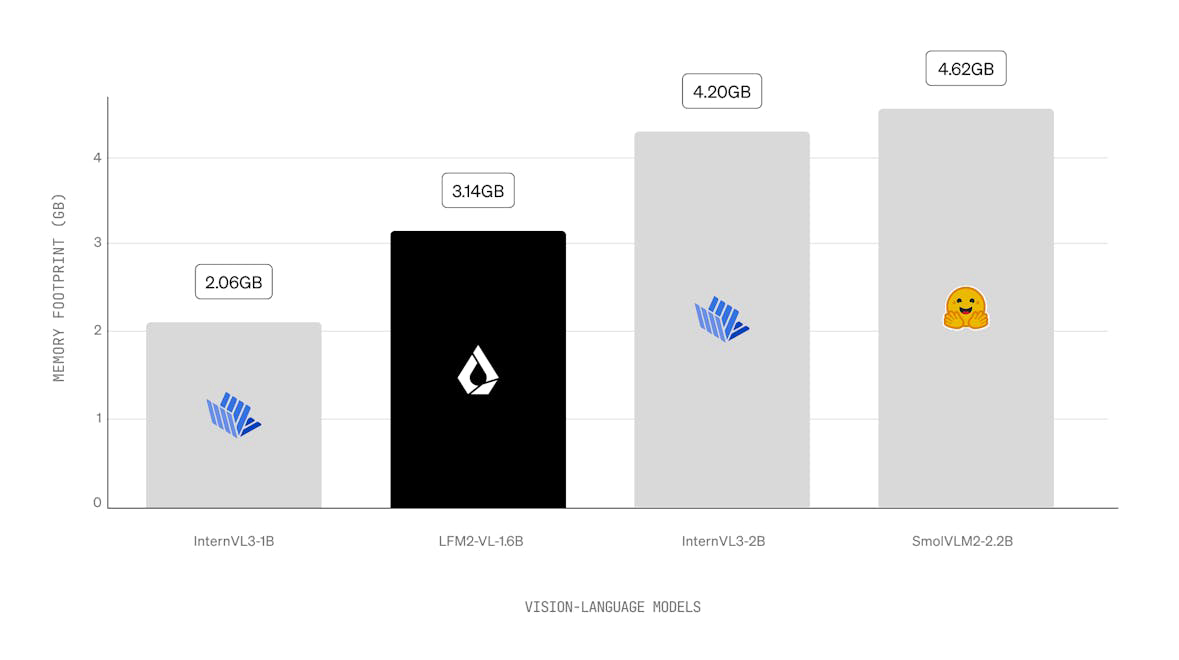
LFM2是一种新型液体基础模型(LFM),在设备生成AI的质量、速度和内存效率方面设定了新标准。LFM2旨在提供最快的设备AI体验,在CPU上比其前身Qwen3提供2倍更快的解码和预填充性能。凭借混合架构,它在每个尺寸类别中显著超越其他模型,使其非常适合本地和边缘用例。LFM2在训练效率上比前几代提高了3倍,为构建强大的通用AI系统提供了具有成本效益的途径。
如何使用 LFM2?
LFM2模型可以通过像llamacpp这样的集成在设备上进行私密和本地测试。用户还可以使用TRL对模型进行特定用例的微调。对于定制解决方案,鼓励用户联系销售团队。
核心功能 LFM2:
1️⃣
在CPU上比Qwen3提供2倍更快的解码和预填充性能
2️⃣
与前一代LFM相比,训练效率提高3倍
3️⃣
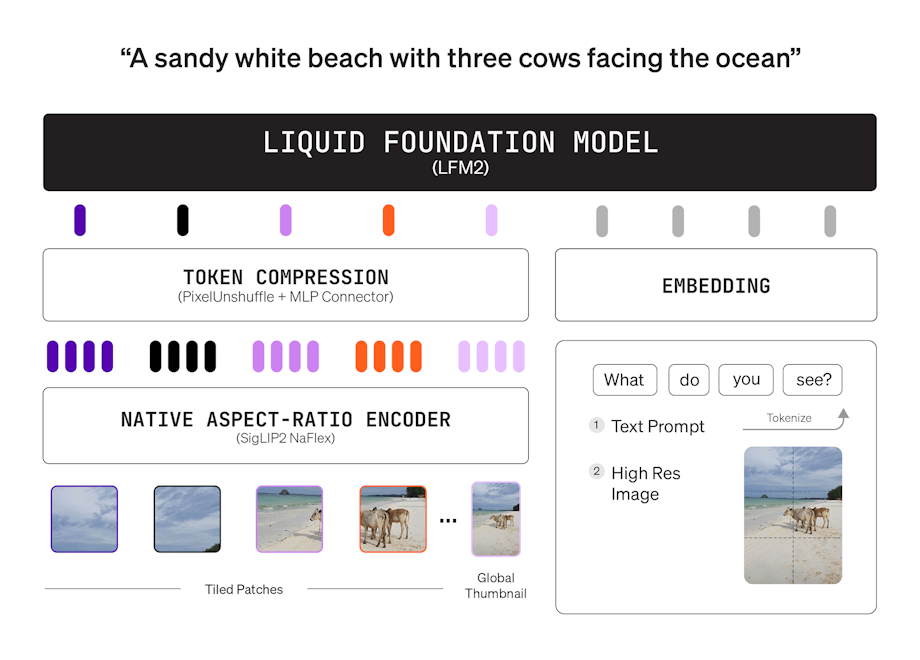
具有乘法门和短卷积的混合架构
4️⃣
在CPU、GPU和NPU硬件上灵活部署
5️⃣
针对智能手机和机器人等各种设备的实时推理进行了优化。
为什么要使用 LFM2?
| # | 使用案例 | 状态 | |
|---|---|---|---|
| # 1 | 消费电子产品中的本地和边缘AI应用 | ✅ | |
| # 2 | 机器人和智能家电的实时推理 | ✅ | |
| # 3 | 在金融、电子商务和教育领域的部署。 | ✅ | |
开发者 LFM2?
Liquid AI Inc.致力于构建在特定任务和硬件要求下平衡质量、延迟和内存的基础模型。他们与财富500强公司合作,提供超高效的多模态基础模型,并配备安全的企业级部署堆栈。